These are the results for our Cubie eval. An eval to test LLMs (see more details exactly why we are building this or what it is here Is your LLM a wordcel or a shape rotator?)
This is a state prediction with gpt-5-high
state prediction: we give an initial state to the cube and a set of moves, and the LLM has to perform those moves on the state and respond with the final state. understand more about moves, levels here: working-verifying
We’ll get right into the results.
I started with just prompting and found the most optimized prompt and got baseline results for the first 5 levels (here, levels mean the number of moves, where level 0 is just the base moves)
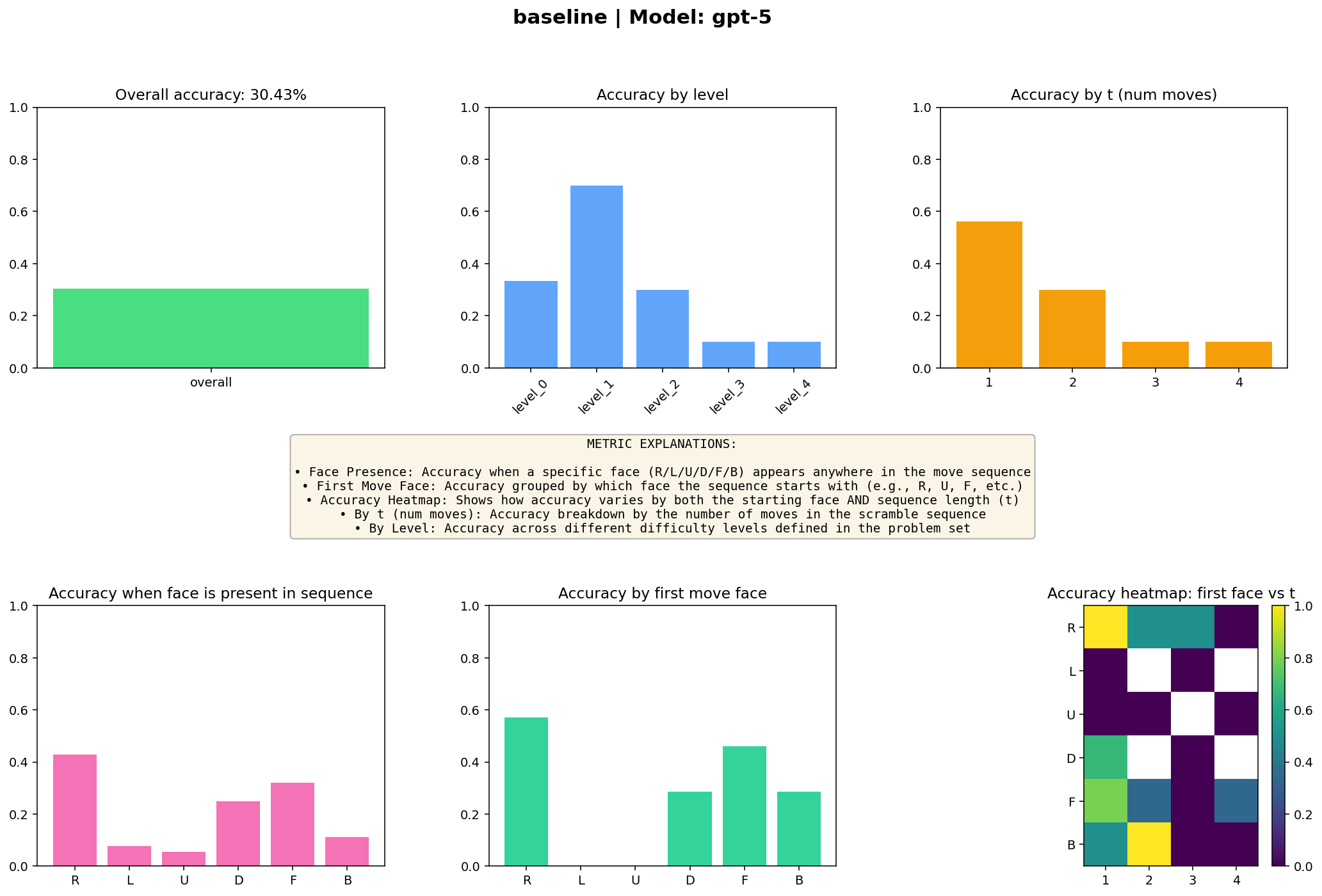 You see that it’s like the model is blind to the U move.
You see that it’s like the model is blind to the U move.
We got this result by carefully optimizing the prompt over multiple tests. You can see the results below
 (I only tested it to solve the top 26 problems to get a feel of how the model performs)
(I only tested it to solve the top 26 problems to get a feel of how the model performs)
See how it never got the U move right (see what it means in working-verifying, tldr: moving the upper layer clockwise). This was such a surprisingly big blind spot for the model that, unless specifically prompted to solve this layer with instructions, it never got it right.
After that, I tried the evolutionary test-time scaling method.
evolutionary test time scaling
Basically, I would spawn a number of agent and ask them to predict the state with some strategy, and then based on their answer, I would give them a score, and they would try to improve their answers.
Since the model is incapable of practically giving itself the right score, what I did here was compare the right answer and the LLM’s answer with a hardcoded algo to fetch a score and pass it to a judge LLM. The judge LLM would give the agent’s answer a score on 5 parameters based on the reasoning traces for each agent to solve it further.
This completely shifted the results!
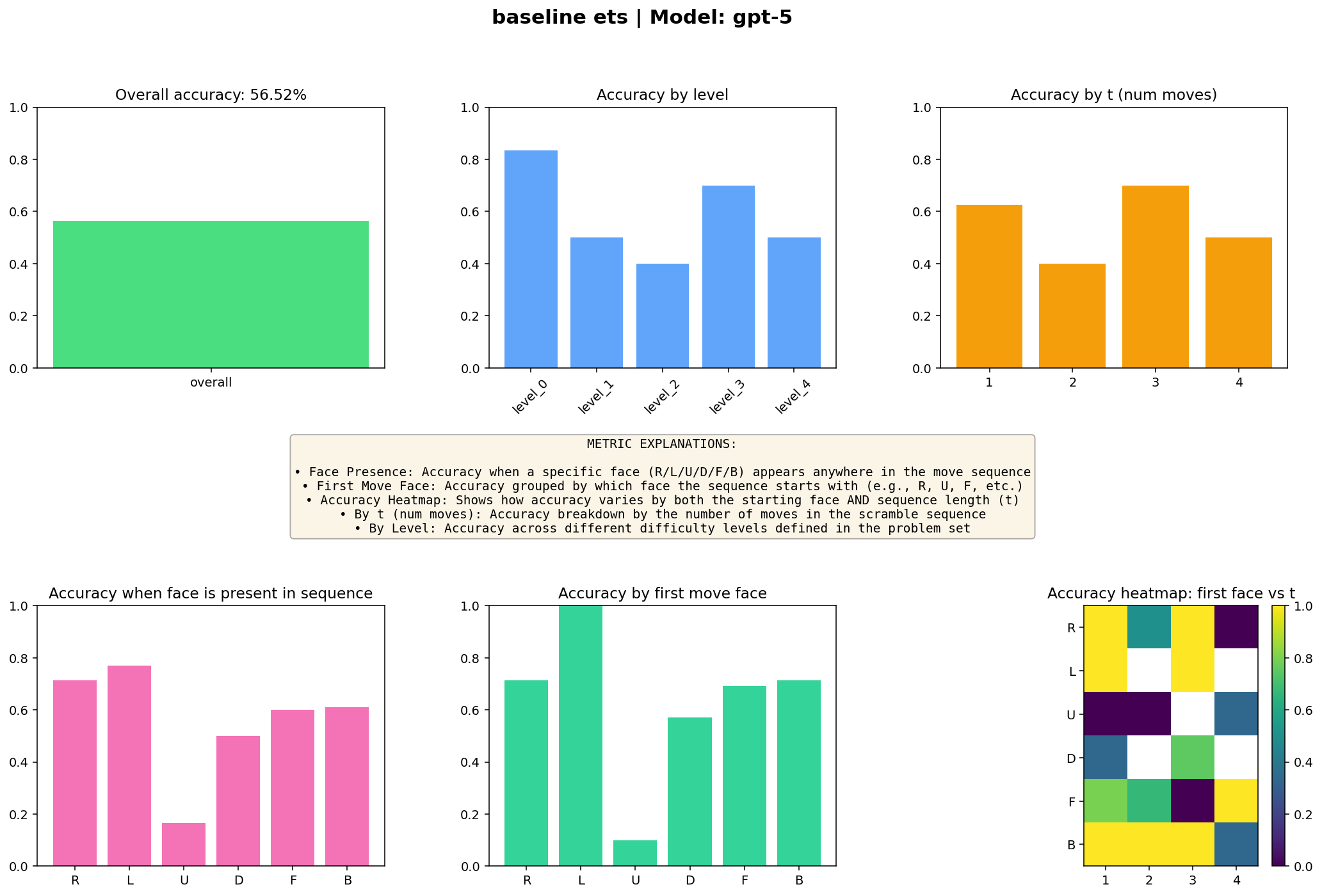
The ETS approach nearly doubled from 36% to 56%
An accuracy of 53% is baffling and amazing. But can you notice that one short bar in accuracy by moving?
The curse of the upper layer
Even after applying ETS, gpt-5-high was still not able to ever get the U moves right. The short number of correct ones you see is actually U2, U1, etc (see what that means in working-verifying, tldr: middle layer, bottom layer).
essentially GPT5 high got all the other answers correct if they didn’t have the face of U.
Why was this the case? And why does gpt-5-high have this major blindspot?
Unless you strictly prompt the model to do it a certain way, the LLM is never moving it right. The answer… overconfidence.
Sounds weird, but when you look at the reasoning traces of each agent and the subsequent judge prompts. It never thinks that it could have moved the upper layer incorrectly. In fact, even if you prompt it to be careful, it ignores that advice in the subsequent generations of ETS.
This is such a surprisingly big blindspot that if gpt-5-high got it right, it would have won the eval with ets…
This is practically more valuable than the model failing in the eval because it reveals great information about its capabilities. Like non-uniform spatial reasoning, being able to imagine most layers except the curse of U
What does this mean, future work…
You can try the eval for yourself. I wrote a small library that you can use to generate the problems and verify the results. i also have a visualizer for these cubes that i also used, if you want to see the cube and your own results. find both of them here visualizer cubes-lib
Testing more models
These were only the results for gpt-5-high, which i was able to perform thanks to the generosity of telt and me eating his token budget. But I do need to test more frontier models, see where they fall short, who knows maybe claude-4.5-sonnet can’t comprehend moving a layer anti-clockwise, or grok 4 is color blind…
Cubie as an eval
Since our results, we do see that it’s a pretty gameable eval given infinite compute and time to run it. So I shift my view to instead of a one-all eval, have this as more of a part of a bigger eval suite.
state prediction being a 1-shot test Two reasons for that:
- We do give the model a hint at the right answer for it to converge. A human can just move it
- Taking infinite compute to do 6 moves sounds stupid
Further tests, there are two more tests after this to be performed.
- Testing if they can actually solve the cube in the shortest route
- Testing if they can move the cube to do specific stuff
If you would like to help me test these models in other various ways, consider sponsoring me some tokens from the frontier models, or cash would also do i could always use some cash. reach me out on X my dm are always open ;)
Acknowledgements
Big thanks to telt for sponsoring the compute and his patience, and helping along the way, also tokenbender for helping along the way and fixing my caveats…