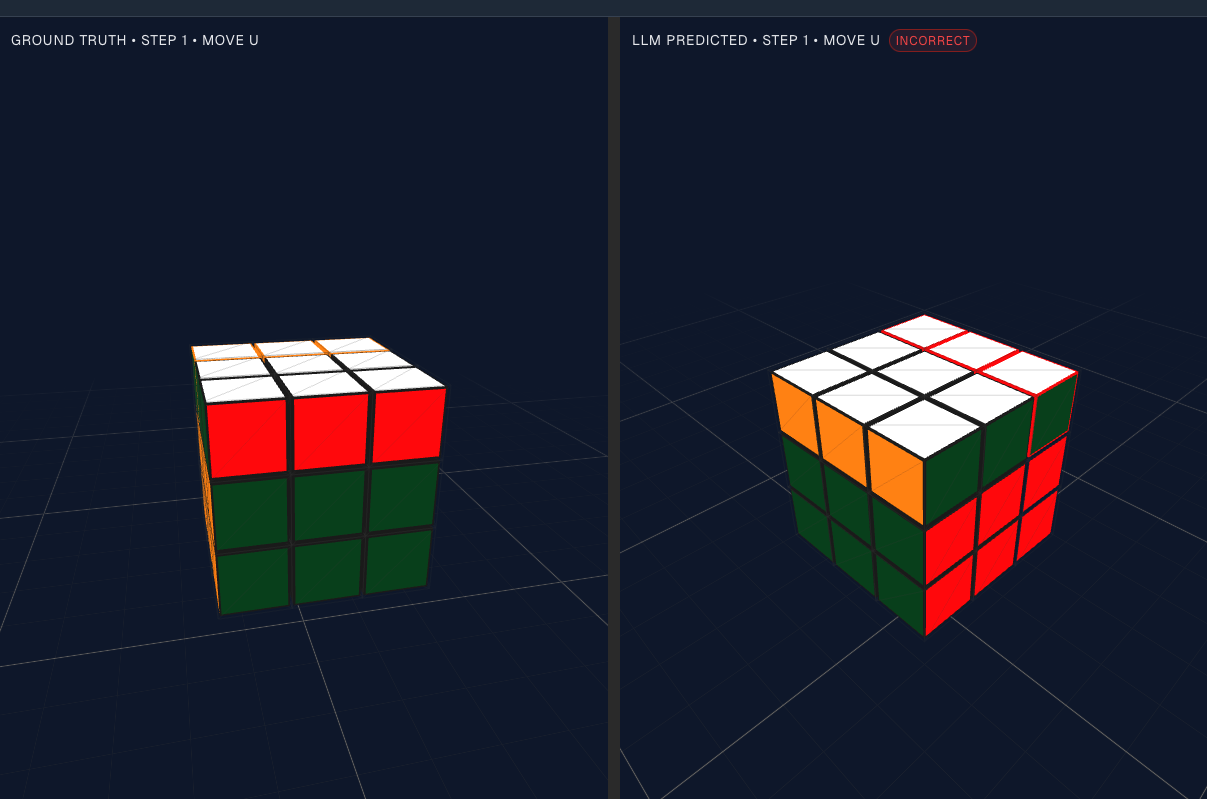
Hold a solved 3×3 cube: green facing you, blue at the back, orange left, red right.
now turn the top layer clockwise once (that’s U in cuber slang).
Look at the top row of the front face (which was all green before).
What color appeared in the centre-top square?
If you said red, you just passed the hardest sub-task for GPT5 high we tested. (skip to the results)
Why a Rubik’s Cube eval?
Most LLMs eval sit at one of two extremes: either the training corpus contains the exact answer, or it contains nothing at all. Cube solving lives in the narrow band between the two. The web is full of move notation, pattern charts, and beginner recipes, but none of them list the precise sequence for your personal scramble. You get generic operators “f r u r’ u’ f’” and must project them onto the coloured plastic in your palm. That small act of discrete transfer, from abstract rule to concrete state, is what the cubie bench measures. So, Rubik’s Cube eval can be one of the truest representations of the model’s internal shape rotation (world model) capabilities.
There’s also a general lack of good evals that actually try to nail and deduct the model’s spatial reasoning, which can be performed in its own latent space. Usually, people take examples of MC-bench, which I found to be a more vibe-based and subjective eval, comparing the perception of what the voter or arc agi, which, even though a smart approach, doesn’t really try to test the model’s spatial reasoning exactly.
And because a solved cube is trivial to verify, it makes a clean way for latent planning. I distilled the probe into three tests.
The three tests
I came up with three verifiable tests for this
- predict the next state: given a starting state and moves, predict the end state of that cube.
- solve the cube : given scrambled starting set solve the cube
- optimal path-finding (A → B in ≤ God’s-number).: given a start state A and an end state B, give the moves to go from A→B taking the shortest path
Note that state here means the orientation of the cube, what color is where.
Constraints
To ensure fairness in this eval, we have a few constraints so as not to contaminate the results and get a true understanding of the model’s internal latent reasoning. The extent to which I tested it was only to provide a pseudo-score in the evolutionary test time scaling approach, without giving explicit scores to the reasoning agent. The main constraints were.
- no finetuning or training beforehand, specific to this eval
- No code execution as a tool; these are in place not to hinder the model’s capabilities, but so as not to give explicit instructions or game the eval for high scores.
Predict the next state
SIDE NOTE: In order to build a better understanding and detailed ablation, I am going to start with only the first test with GPT-5 to get a baseline result and compare it with other models and techniques.
The task is forward simulation: start position plus move list, return the sticker cube.
I bucket problems into five levels, one to five moves. Each level holds ten prompts: the first five begin from the solved state, the last five from a random scramble. For now, the ceiling is five turns enough to expose errors without drowning the trace window.
A generator script can spit out infinite samples, but I wanted a graded curve. A tiny complexity estimator scores each scramble by (a) move count, (b) number of distinct layers touched, (c) hamming distance of every cubie from its start slot. the details live in complexity theory.
Results
You can see the preliminary results that we ran on models in results