this is a paper my meta lcm
token embeddings
starting with embedding. so in traditional transformers we first convert our datraset into tokens and then embed it here instead of that we just use SONAR to convert each sentence into it’s embeddings called as concept embeddings.
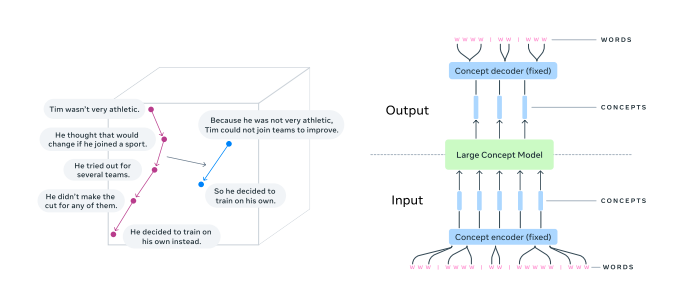 the idea is it would learn concepts instead of tokens so instead of predicting next token it predicts the next concept which in theory would be lot more knowledge dense
the idea is it would learn concepts instead of tokens so instead of predicting next token it predicts the next concept which in theory would be lot more knowledge dense
dataset
so i created a dataset for this but it sucks i forgot to add pre filters like charchter lenght etc… also, i checked the dataset i created with colab was also very good and infact pretty similar to the one i created with google cloud compute spending 200 rs and idk how much of my time so it is essentially wasted ig i will just continue with using the same dataset strategy for colab
- use colab one
- always filter out your datasets think of how you can avoid doing work in it later anyways i have about 88,000 rows of data in each one of them maybe tomorrow i will get the colab script to run again after a certain checkpoint and automatically push to huggingface dataset and merge all of that in anycase i have some amount of embedded dataset that i can used directly i will try to train the nanogpt size model to see if it can predict anything with any luck it might work
the problem still appears to be that the loss is dropping way too quickly and then nothing happens seems counterintuitive but let’s see
wait if you have the embeddings and you give some text as input how does the model know what to predict you can’t cut the embeddings in half FUCK this could be the training flaw what is wrong with me it is a continous embedding now i know what it means
ok the dataset seems to be correct its the same as tokens but instead sentence embeddings for the next embedding sequence as a context of previous ones
training
so i tried a bunch of things
costllm
our initial script was using MSE loss which as we know went down extremely fast and the outputs were nowhere near what we wanted
i though that it was because even if one percent error in the embedding if it is at the wrong place it causes it to completely change the meaning of the embedding so what i did was use a cosine similarity loss
which then gave us this
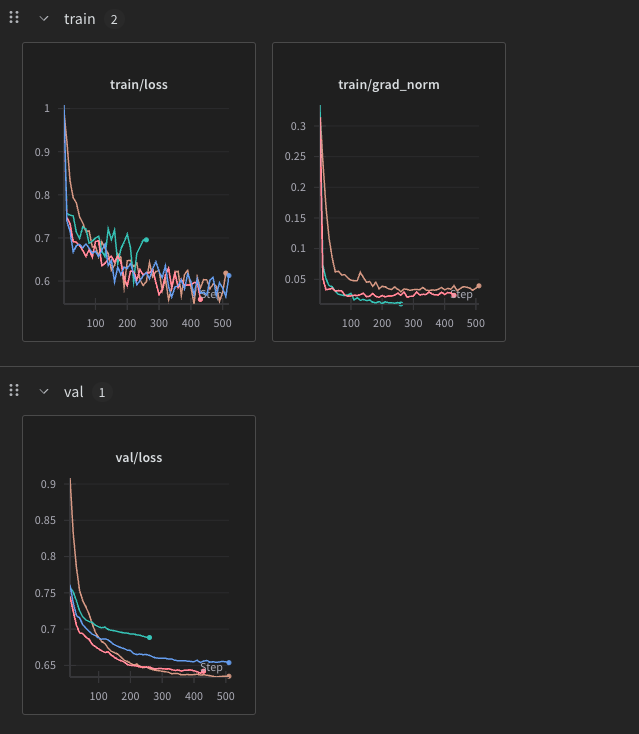 these are a bunch of runs but you can get an essence in this graph
these are a bunch of runs but you can get an essence in this graph 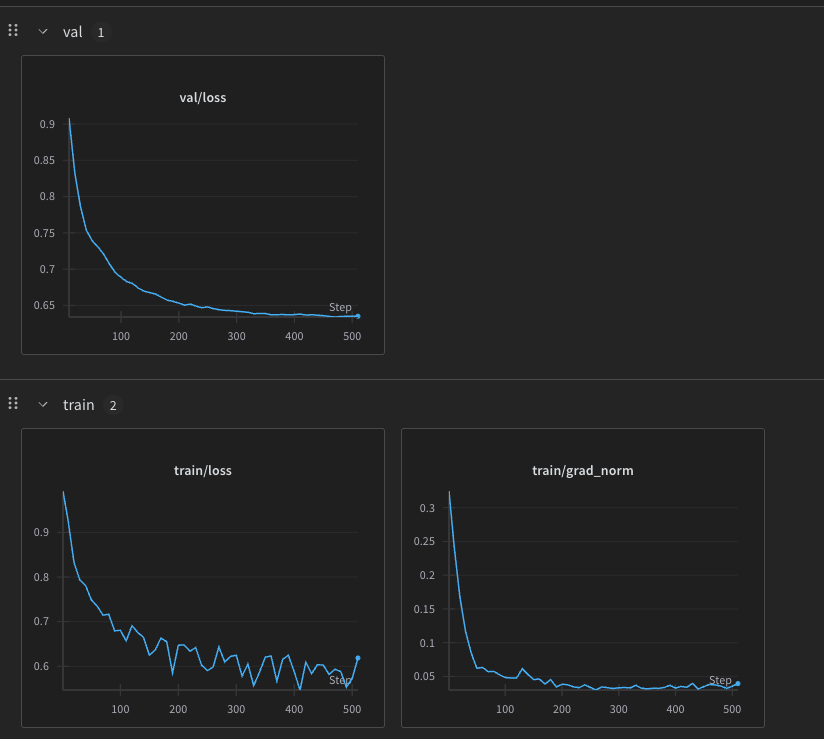 now the llms suggest this because it is overfitting and i think soo too
im not sure if my dataset is too small
i have tried a lot of lr tweaks but the final issue is because of the loss plataeuing around 0.6 which is a real problem
now the llms suggest this because it is overfitting and i think soo too
im not sure if my dataset is too small
i have tried a lot of lr tweaks but the final issue is because of the loss plataeuing around 0.6 which is a real problem
i have a list of things i can try now
- increase param size
increase dataset size- change loss to somehting mse+cosine similarity hybrid
i am thinking of doing a simple test run of the training script from the lcm repository too maybe something weird in my implementation(can’t because it uses FUCKING FAIRSEQ2)- Add PreNet and PostNet Residual Connections (from claude)
i think it is also time i get someone’s opinion on this
i haven’t gotten much opinions on this yet i have blabbered about it a lot
small update the last run was actually reduce the loss little by little until it it didn’t
i also tried to increase the dataset size to 200k sentences no improvment still i have moved the dataset gen to local also so it’s easier now i am running SONAR repo locally
I also cloned the lcm repository and maybe i will just try to run its training script in the code
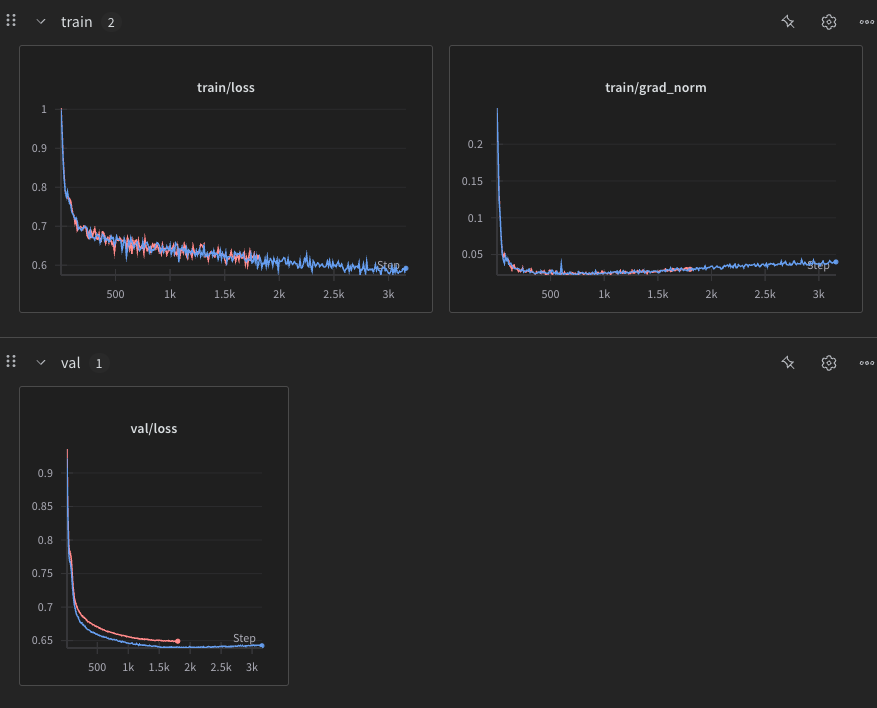 (the above was the two training runs i did cosine 200k)
ig the only thing i can try now is to make the large concept model github script run see if it gives any improvements if not ig i will just give up on this project
(the above was the two training runs i did cosine 200k)
ig the only thing i can try now is to make the large concept model github script run see if it gives any improvements if not ig i will just give up on this project
although i haven’t tried MSE loss with the now big dataset maybe if it is now big enough it can finally actually work
or i just try a bunch of fucking losses
tllm
new stuff may 8-10
well turns out the model works quite well with mse loss it wen’t quite low and is giving out coherent stuff with a lower cosine similarity than the cosine simialirity so maybe i just wait see where it plateues on it
but good results so far
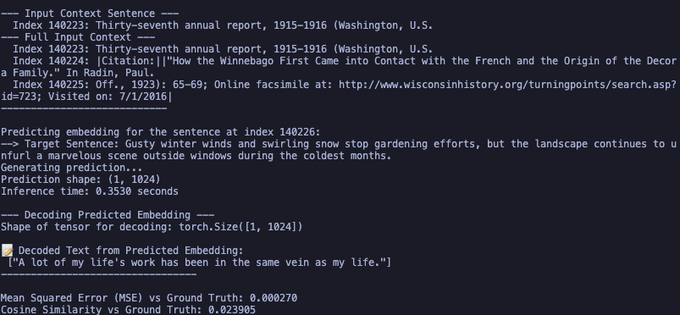 maybe the final fix is just inventing a new loss for embedding comparison
something mix with MSE
maybe the final fix is just inventing a new loss for embedding comparison
something mix with MSE
let’s ask claude ig
claude suggested two things
- normalized embeddings before loss
- combined loss with cosine simialrity
normalized embeddings before the loss
this was simple change we just let
def mse_loss(pred, target):
# Normalize pred and target vectors before calculating MSE
pred_normalized = pred / jnp.linalg.norm(pred, axis=-1, keepdims=True)
target_normalized = target / jnp.linalg.norm(target, axis=-1, keepdims=True)
return jnp.mean((pred_normalized - target_normalized) ** 2)it started with a loss of 0.002 and it severly overfit the dataset as you can see (similar effect to when we used cosine similarity as a loss)
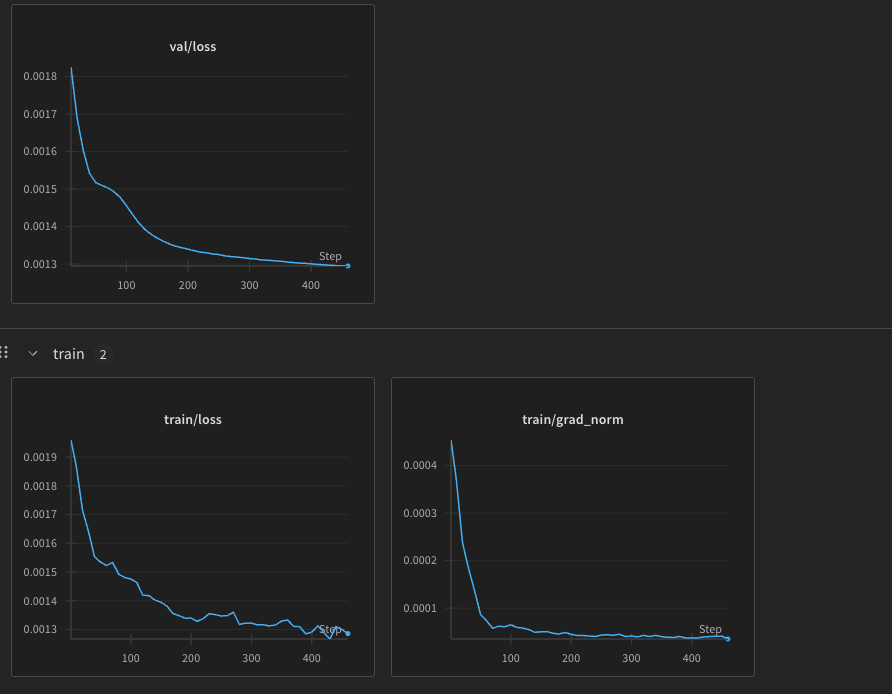
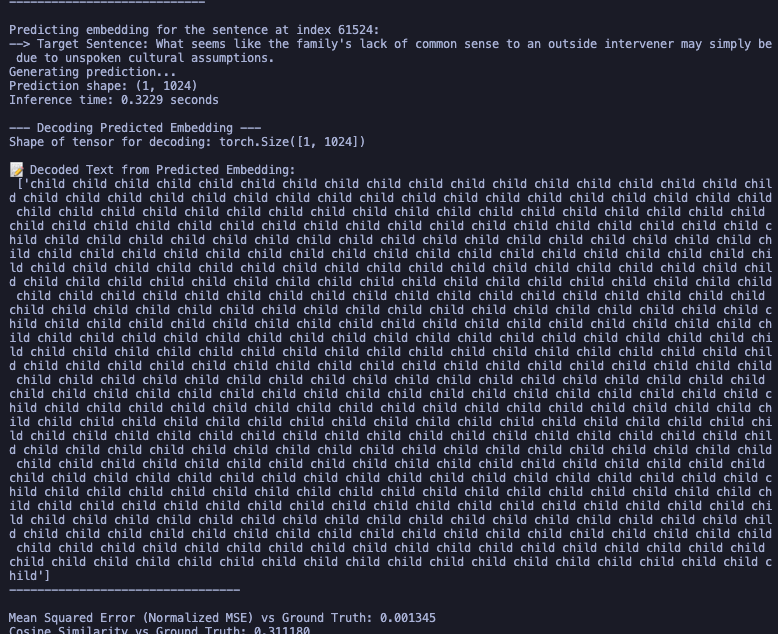
i don’t think this is really doing anything so i will move to the combined loss
cosine-mse combined loss
claude suggested to use a combined loss and gave a simple formula
where norm is
norm_constraint = jnp.mean(jnp.abs(jnp.linalg.norm(pred, axis=-1) -jnp.linalg.norm(target, axis=-1)))and coeff is a normal integer
this seems like the basic formula used everywhere to find a new one i would have to map shit which i can’t right now so let’s not it might very well be that i would need to just use MSE at the end but nothing wrong in checking perphaps starting with α = 0.7 (cosine usually gives bad performance so we keep it less) this was a bust also despite a promising loss curve it weirdly never converges to the actual data only outputs one embedding for a while so ig this is not it
wait the fuicking gemini was normalizin them and we know that is not good im gonna try again
fuck yes this works much better than mse and cosine loss lessgoo
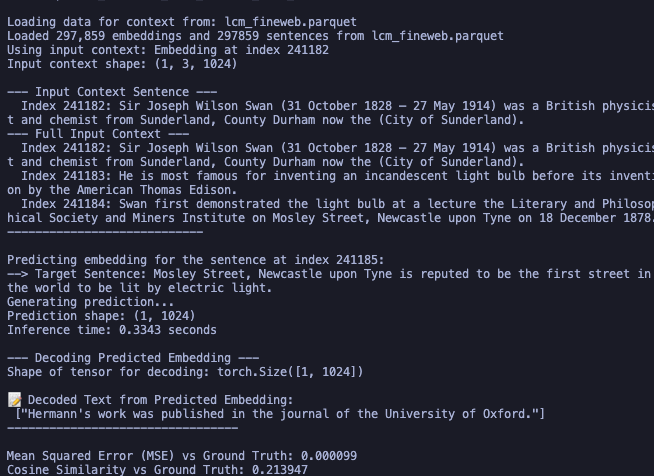
grad norm is super fucking weird though
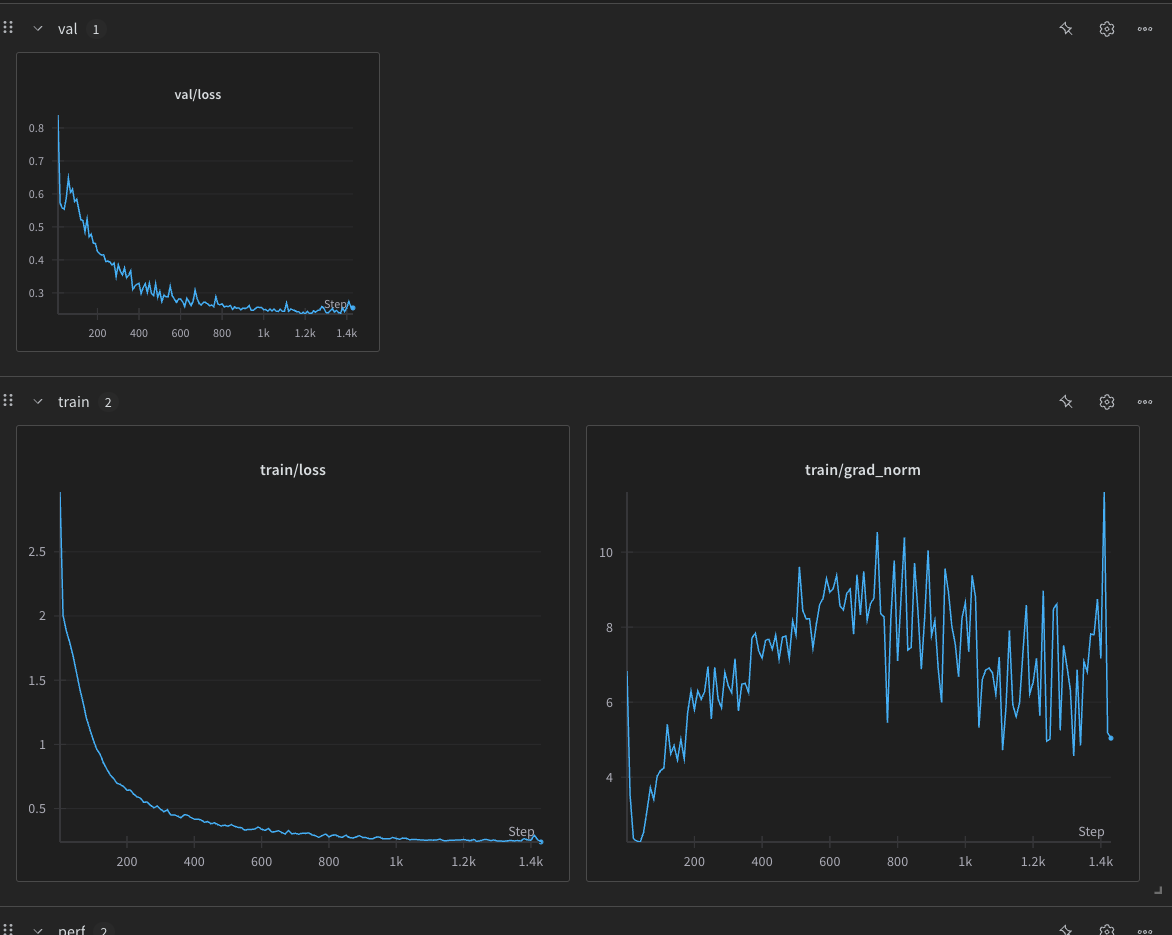
fuck me either this was just a flook or something very wierd happend i ran this again at 13 today last was 11 and it got fucked totally after some checking it’s down to tow things
- either the normalized constraint shouldn’t exist
- it should exist and in my last train i first ran it with 0.1 and then with 0.5 after 210 iterations as given in the wandb logs
weird shit
i am very scared i finally had a good model going but didn’t fucking budge
i do have the checkpoints for it though

second one was the correct one LET’S FUCKING GOOOO maybe i can do a dynamic normalizing coefficient since that is what is driving the improvment waow
i read about layer norm today and it is a standard use for whatever we do in transformers maybe i should try it but it works kind of awesome right now so i am not sure what is happening nvm claude told me it is correct
ig now i only test it with the variable norm coeff and i can poast we can try a few dynamic losses
1. curriculam
Behavior: Starts very low (0.05), gradually increases with a smooth S-curve to final weight (0.5)
-
Early: Focus on semantic learning (MSE + cosine similarity)
-
Middle: Gradual introduction of magnitude constraints
-
Late: Strong enforcement of norm alignment
fuck this none of this dynamic weight is not working i will just have a manual switching
Why it works: Mimics your successful manual approach but automates the transition
didn’t work so i changed initial loss to 0.1 and it still didn’t work
this is our loss algo
final run results
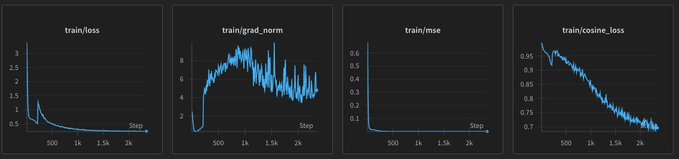
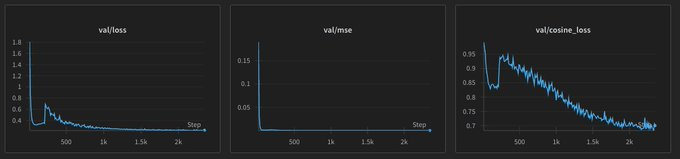
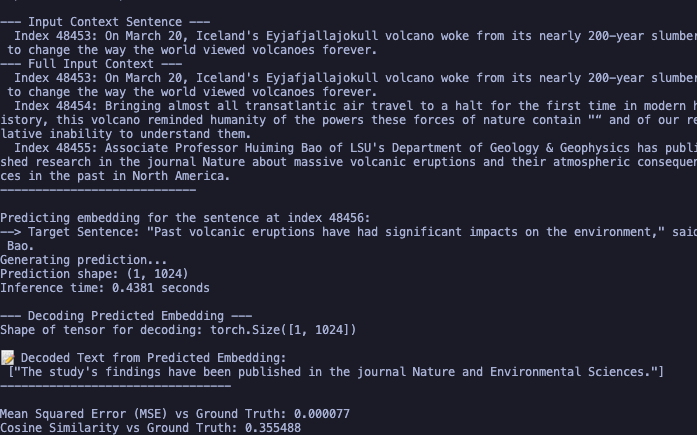
triplet loss
you have three variables positive , negative and anchor ok wait this is bullshit
ideas to try later
- mix with thinking models to force concepts in thought chains
- the SAE paper to force concepts
- concept reward in r1 type models for correct concept direction